# set randomization for seeding population mean
set.seed(827)
# pick a population mean that will be fixed but unknown to us
true.mean <- sample(3:8, size=1)4.1: Maximum Likelihood Estimation
![]()

In Chapter 3, we explored properties of sample statistics picked from a population with a known distribution.
- We analyzed the distribution of sample means picked from normal and exponential distributions.
- We analyzed the distribution of sample proportions independently picked from a binomial population.
- Sampling distributions allowed us to predict how likely we are to pick certain sample statistics when the population is fixed and known.
However, statistical inference is applied in situations where properties of the populations are unknown. A typical workflow for statistical inference is:
- Pick one (not thousands) random sample from a population with unknown characteristics.
- Calculate sample statistic(s) to describe the sample.
- Based on the characteristics of the sample, make predictions/estimates for the unknown population characteristics.
In this chapter, we explore two powerful estimation techniques, maximum likelihood estimation and the method of moments. We will investigate how well our estimators perform using general properties of estimators such as bias, variability, and mean square error.
Case Study: Slot Machine Jackpots

A strategic gambler believes they have identified a faulty slot machine which pays out significantly more money than the other slot machines. She and her friends watched the machine 24 hours a day for 7 days and observed the slot machine paid out the $\(1,\!000,\!000\) jackpot prize 10 times during the week. How can she figure out whether the machine is faulty or whether the number of jackpot prizes are within reason?
Question 1
They decide to compare the performance of the suspect slot machine to other slot machines. They pick a random sample of \(n=4\) other slot machines and record how many jackpot prizes each machine pays over a one week time frame. Let random variable \(X\) denote the number of jackpots a randomly selected slot machine pays out in week. What distribution do you think best models \(X\)? Give a corresponding formula for the probability mass function of \(X\).
- Hint: Should we use a discrete or continuous random variable?
- Hint: See either appendix of common discrete random variables or appendix of common continuous random variables for additional help.
Solution to Question 1
Collecting Data
We will simulate collecting a data sample.
- Run the code cell below to “secretly” generate a population mean that we store in
true.mean. - The command
set.seed(827)will seed the randomization so we all have the same population mean. - Do not print the output to screen. Keep
true.meansecret for now!
Next, we generate a sample of size \(n=4\).
- Run the code cell below to generate your random sample.
- Each observation \(x_i\) in the vector
xcorresponds to the number of jackpots a randomly selected slot machine paid out in one week. - The command
set.seed(612)will seed the randomization so my samplexremains fixed.- You can delete the command
set.seed(612)to generate a different random sample picked from the same population. - Then you can compare the estimate obtained from your sample with the estimate based on the sample generated below.
- You can delete the command
- Inspect the values in your sample after running.
set.seed(612)
x <- rpois(4, true.mean)
x[1] 9 8 6 5- The sample generated by
set.seed(612)is
\[x_1=9 \ ,\ x_2=8\ ,\ x_3=6 \ , \ x_4=5.\]
Question 2
Using the probability mass function from Question 1 and your sample generated by the code cell above stored in x, what is the probability of picking the random sample \(x_1\), \(x_2\), \(x_3\), \(x_4\) stored in x? Your answer will be a formula that depends on the parameter \(\lambda\).
Solution to Question 2
What Is the Probability of Picking Our Random Sample?
We motivate maximum likelihood estimation with the following question:
What is the most likely value for the unknown parameter \(\theta\) given we know a random sample of values \(x_1, x_2, \ldots x_n\)?
The likelihood function \[\color{dodgerblue}{L(\theta)= L( \theta \mid x_1, x_2, \ldots x_n)}\] gives the likelihood of the parameter \(\theta\) given the observed sample data. A maximum likelihood estimate (MLE), denoted \(\color{dodgerblue}{\mathbf{\hat{\theta}_{\rm MLE}}}\), is the value of \(\theta\) that gives the maximum value of the likelihood function \(L(\theta)\).
Note
In statistics, we typically use Greek letters to denote population parameters, and we use “hat” notation to indicate an estimator for the value of a population parameter.
- The notation \(\theta\) is the generic notation typically used to represent a parameter.
- The notation \(\hat{\theta}\) denotes an estimator for \(\theta\).
Question 3
Find the value of \(\lambda\) that maximizes the likelihood function from Question 2.
Tip
Recall from calculus that global maxima occur at end points or critical points where \(\frac{d L}{d \lambda} = 0\) or is undefined.
Solution to Question 3
Plotting the Likelihood Function for Question 3
Given the random sample \(x_1=9, x_2=8, x_3=6, x_4=5\), the resulting likelihood derived in Question 2 is
\[L({\color{tomato}\lambda}) = \frac{{\color{tomato}\lambda}^{28} e^{-4{\color{tomato}\lambda}}}{(9!)(8!)(6!)(5!)}.\]
In Question 3, we find the value of \(\lambda\) that maximizes the likelihood function \(L(\lambda)\) using optimization methods from calculus. It is always a good idea to check our work. If we have access to technology, we can plot the likelihood function and identify the approximate value of \(\lambda\) that gives the maximum value of \(L(\lambda)\).
lam <- seq(3, 11, 0.1) # values of lambda on x-axis
like.est <- lam^(sum(x)) * exp(-4*lam)/prod(factorial(x)) # values of L(lambda)
plot(lam, like.est, # plot lam and likelihood on x and y axes
type = "l", # connect plotted points with a curve
ylab = "L(lambda)", # y-axis label
xlab = "lambda", # x-axis label
main = "Plot of Likelihood Function") # main label
points(x = 7, y = 0.0002515952, cex = 2, pch = 20, col = "tomato") # point at max
axis(1, at=c(7), col.axis = "tomato") # marking MLE estimate
abline(v = 7, col = "tomato", lwd = 2, lty = 2) # marking MLE estimate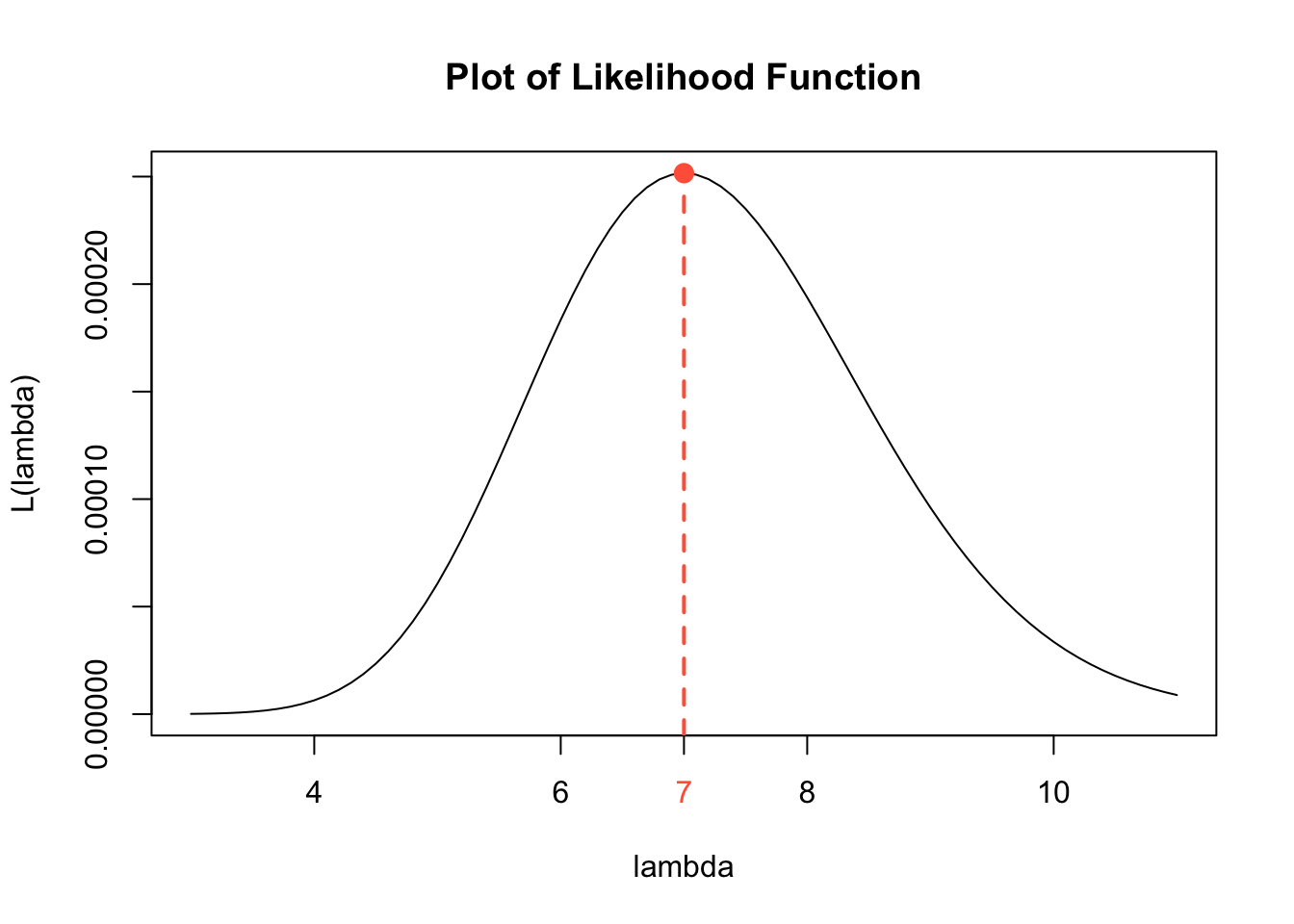
Revealing the Actual Value of \(\lambda\)
We picked a value for \(\lambda\) and stored it in true.mean. We have not revealed what the actual value of \(\lambda\) is. Run the code cell below to see that actual value of \(\lambda\), and compare your answer for \(\hat{\lambda}_{\rm{MLE}}\) in Question 3 with the actual value of \(\lambda\).
true.mean[1] 8A Formula for the Likelihood Function
Let \(f(x; \theta)\) denote the pdf of a random variable \(X\) with associated parameter \(\theta\). Suppose \(X_1, X_2, \ldots , X_n\) are random samples from this distribution, and \(x_1, x_2, \ldots , x_n\) are the corresponding observed values.
\[\color{dodgerblue}{\boxed{L(\theta \mid x_1, x_2, \ldots , x_n) = f(x_1; \theta) f(x_2; \theta) \ldots f(x_n; \theta) = \prod_{i=1}^n f(x_i; \theta).}}\]
Important
In the formula for the likelihood function, the values \(x_1, x_2, \ldots x_n\) are fixed values, and the parameter \(\theta\) is the variable in the likelihood function. We consider what happens to the value of the \(L(\theta)\) when we vary the value of \(\theta\). The MLE \(\hat{\theta}_{\rm{MLE}}\) is the value of \(\theta\) that gives the maximum value of \(L(\theta)\).
Defining the Likelihood Function in R
In Question 2 we derived an expression for the likelihood function \(L(\lambda)\) given the random sample of \(n=4\) values we picked from \(X \sim \mbox{Pois}( \lambda)\) and stored in the vector x. Recall Poisson distributions have pmf
\[f(x; \lambda) = \frac{\lambda^x e^{-\lambda}}{x!} \qquad \mbox{for } x = 0, 1, 2, \ldots .\]
If we pick a sample of \(n=4\) values we denote \(X_1 = x_1\), \(X_2 = x_2\), \(X_3 = x_3\), and \(X_4 = x_4\), then the likelihood function is
\[L(\lambda) = L(\theta \mid x_1, x_2, \ldots , x_n) = \left( \frac{\lambda^{x_1} e^{-\lambda}}{x_1!} \right) \left( \frac{\lambda^{x_2} e^{-\lambda}}{x_2!} \right) \left( \frac{\lambda^{x_3} e^{-\lambda}}{x_3!} \right) \left( \frac{\lambda^{x_4} e^{-\lambda}}{x_4!} \right).\]
We will use the random sample generated by the code cell below. Note x is a vector consisting of values x[1] \(=9\), x[2] \(=8\), x[3] \(=6\), and x[4] \(=5\).
set.seed(612)
x <- rpois(4, true.mean)
x[1] 9 8 6 5Defining the Likelihood Function as Product
In the code cell below, we input the likelihood function.
- To define a symbolic function, we use the command
function(lam) [expr].- We use
lamto denote our variable, \(\lambda\). - We enter an appropriate formula in place of
[expr].
- We use
[expr]is the product of the \(4\) pmf’s of the Poisson distribution.- We name the newly created function
like. - To evaluate the function
likeat \(\lambda = 7\), we use the commandlike(7).
like <- function(lam) lam^x[1] * exp(-lam)/factorial(x[1]) *
lam^x[2] * exp(-lam)/factorial(x[2]) *
lam^x[3] * exp(-lam)/factorial(x[3]) *
lam^x[4] * exp(-lam)/factorial(x[4])
like(7)[1] 0.0002515952Improving the Code for a Likelihood Function
If we have a sample size \(n=100\) instead of \(n=4\), we would not want to code the likelihood as we did in the previous code cell. We can streamline the code using vectorized functions. In the slot machine example, we have \(X \sim \mbox{Pois}(\lambda)\) and a sample \(x_1=9\), \(x_2=8\) , \(x_3=6\), and \(x_4=5\).
- In a previous code cell, we stored the sample in the vector
x\(= (9, 8, 6, 5)\). - We create the vector
pmfas follows:lam^xis the vector \(\left( \lambda^9, \lambda^8 , \lambda^6 , \lambda^5 \right)\).exp(-lam)/factorial(x)is the vector \(\left( \frac{e^{-\lambda}}{9!}, \frac{e^{-\lambda}}{8!}, \frac{e^{-\lambda}}{6!}, \frac{e^{-\lambda}}{5!} \right)\).- The product of these two vectors in R results in the vector
pmf,
\[\mbox{pmf} = \left( \lambda^9 \cdot \frac{e^{-\lambda}}{9!}, \lambda^8 \cdot \frac{e^{-\lambda}}{8!}, \lambda^6 \cdot \frac{e^{-\lambda}}{6!}, \lambda^5 \cdot \frac{e^{-\lambda}}{5!} \right).\]
- The function
prod(pmf)will take the product of all entries in the vectorpmf,
\[\mbox{like(lam)} = \left( \frac{\lambda^9 e^{-\lambda}}{9!} \right) \cdot \left( \frac{\lambda^8 e^{-\lambda}}{8!} \right) \cdot \left( \frac{\lambda^6 e^{-\lambda}}{6!} \right) \cdot \left( \frac{\lambda^5 e^{-\lambda}}{5!} \right). \]
Once we define the function like, we can substitute different values for the parameter \(\lambda\) into the function like and compute values of the likelihood function. Run the code cell below to compute the likelihood that \(\lambda = 7\) given the sample x.
like <- function(lam){
pmf <- lam^x * exp(-lam)/factorial(x)
prod(pmf)
}
like(7)[1] 0.0002515952Using Built-In Distribution Functions
For many common distributions, R has built in functions to compute the values of pmf’s for many discrete random variables and pdf’s for continuous random variables. For Poisson distributions, the function dpois(x, lam) calculates the value of \(f(x; \lambda) = \frac{\lambda^{x} e^{-\lambda}}{x!}\).
- Therefore, we can use
dpois(x, lam)in place of the expressionlam^x * exp(-lam)/factorial(x). - The code cell below makes use of the
dpois(x, lam)function and saves us the trouble of typing the formula out ourselves! - Run the code to evaluate the function at \(\lambda = 7\) to make sure the result is consistent with our previous functions.
like <- function(lam){
pmf <- dpois(x, lam)
prod(pmf)
}
like(7)[1] 0.0002515952Optimizing the Likelihood Function in R
In Question 3 we used methods from calculus to find the value of \(\theta\) that maximizes the likelihood function \(L(\theta)\). We can check those results using the command optimize(function, interval, maximum = TRUE).
functionis the name of the function where we stored the likelihood function.intervalis the interval of parameter values over which we maximize the likelihood function.- Using
c(0,100)means we will find the maximum of \(L(\theta)\) over \(0 < \lambda < 100\). - Based on the values in our sample, we can narrow the interval to save a little computing time.
- Using
maximum = TRUEoption meansoptimize()will identify the maximum of the function.- Note the default for
optimize()is to find the minimum value.
- Note the default for
- Run the command below to calculate \(\hat{\lambda}_{\rm{MLE}}\) for the slot machine example.
optimize(like, c(0,100), maximum = TRUE)$maximum
[1] 7.000001
$objective
[1] 0.0002515952A First Look at Properties of MLE’s
The random sample \((9,8,6,5)\) picked from \(X \sim \mbox{Pois}(\lambda)\) gave \(\hat{\lambda}_{\rm{MLE}} = 7\). If we pick another random sample \(n=4\) from the population \(X \sim \mbox{Pois}(\lambda)\), how much will our estimate for \(\hat{\lambda}_{\rm{MLE}}\) change? Some desirable properties for the distribution of \(\hat{\lambda}_{\rm{MLE}}\) values from different random samples would be:
- We would like the estimates to be unbiased.
- We would like, on average, \(\hat{\lambda}_{\rm{MLE}}\) to equal the actual value of \(\lambda\).
- In other words, we would like \(\color{dodgerblue}{E \left(\hat{\lambda}_{\rm{MLE}} \right)=\lambda}\).
- Hopefully the values of \(\hat{\lambda}_{\rm{MLE}}\) do not vary very much from sample to sample.
- One way to measure this is to consider \(\color{dodgerblue}{\mbox{Var} \left( \hat{\lambda}_{\rm{MLE}} \right)}\).
- The smaller \(\mbox{Var} \left( \hat{\lambda}_{\rm{MLE}} \right)\) the better.
- The variance, \(\mbox{Var} \left( \hat{\lambda}_{\rm{MLE}} \right)\), measures the precision or variability of \(\hat{\lambda}_{\rm{MLE}}\)
- We hope the estimates make practical sense.
Question 4
If population \(X \sim \mbox{Pois}(\lambda)\) is the number of jackpot payouts a randomly selected slot machine has in one week:
- What is the practical interpretation of the value of \(\lambda\)?
- If we pick a random sample of 4 slot machines and find \(x_1=9\), \(x_2=8\) , \(x_3=6\), and \(x_4=5\), explain why an estimate \(\hat{\lambda}_{\rm{MLE}} = 7\) makes practical sense.
Solution to Question 4
Picking Another Random Sample
The random sample \((9,8,6,5)\) picked from \(X \sim \mbox{Pois}(\lambda)\) gave \(\hat{\lambda}_{\rm{MLE}} = 7\). The actual value of \(\lambda\) we revealed the true.mean we used was \(\lambda = 8\). Below we simulate picking another random sample of \(n=4\) values from the same population, \(X \sim \mbox{Pois}(8)\). Then we will compute \(\hat{\lambda}_{\rm{MLE}}\) for this sample and see if we can start to pick up on a pattern.
- Run the code cell below to generate a new random sample stored in
new.x.
set.seed(012) # fixes randomization
new.x <- rpois(4, 8) # pick another random sample n=4 from Pois(8)
new.x # print results[1] 4 11 13 6The new sample is \(x_1=4\), \(x_2=11\) , \(x_3=13\), and \(x_4=6\).
- Run the code cell to compute the value of \(\hat{\lambda}_{\rm{MLE}}\) for this new sample.
# be sure to first run code cell above to create new.x
new.like <- function(lam){
new.pmf <- dpois(new.x, lam)
prod(new.pmf)
}
optimize(new.like, c(0,100), maximum = TRUE)$maximum
[1] 8.500015
$objective
[1] 1.589466e-05Comparing Estimates
Let’s compare the two random samples and their corresponding values for the MLE estimate.
| Sample | Value of MLE |
|---|---|
| \((9, 8, 6, 5)\) | \(7\) |
| \((4, 11, 13, 6)\) | \(8.5\) |
- Neither gives the correct value for \(\lambda\) which is actually 8.
- One estimate is too small and the other is too large.
- We hope if we average all such MLE estimates together, we get the actual value \(\lambda = 8\).
- We have some sense of the variation, but generating many (10,000) random samples and looking at the distribution of many more MLE estimates will tell us more information about the variability.
Analyzing a Distribution of MLE’s
The for loop in the code cell below generates a distribution of MLE’s for \(\lambda\) based on 10,000 random samples size \(n=4\) picked from \(X \sim \mbox{Pois}(8)\). Inside the for loop we:
- Pick a random sample size \(n=4\) stored in
temp.x. - Calculate the MLE based on
temp.xthat we store in the vectorpois.mle.
Then we plot a histogram to display pois.mle, the distribution of MLE’s from the 10,000 random samples each size \(n=4\)
- Run the code cell below to generate and plot a distribution of MLE’s.
pois.mle <- numeric(10000)
for (i in 1:10000)
{
temp.x <- rpois(4, 8) # given random sample
like.pois <- function(lam){ # define likelihood function
pmf.pois <- dpois(temp.x, lam)
prod(pmf.pois)
}
pois.mle[i] <- optimize(like.pois, c(0,100), maximum = TRUE)$maximum # find max of likelihood function
}
hist(pois.mle,
breaks = 20,
xlab = "MLE",
main = "Dist. of MLE's for Poisson Dist")
abline(v = 8, col = "blue", lwd = 2) # plot at actual value of lambda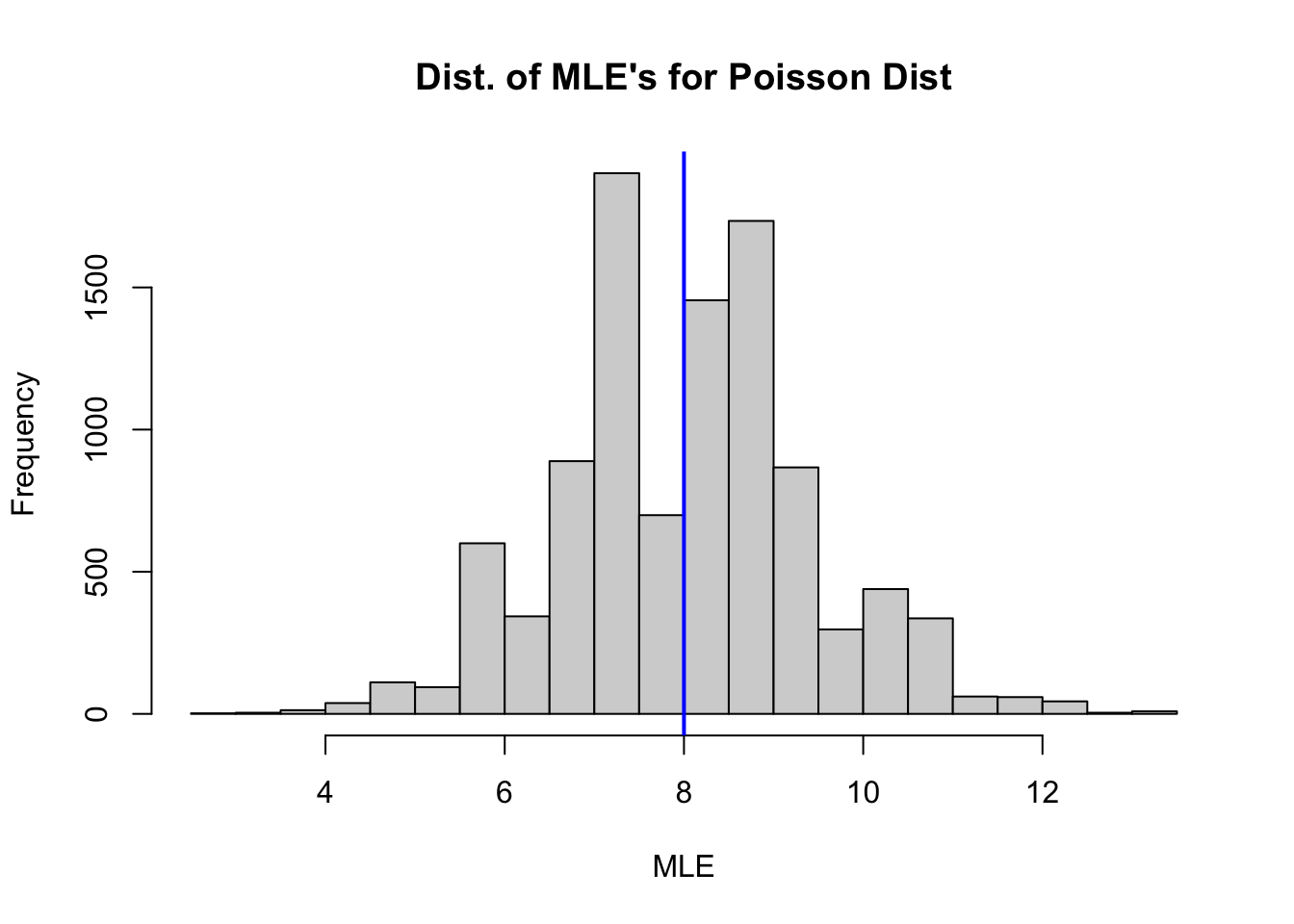
Question 5
Calculate the mean and variance of the distribution of MLE’s stored in mle.pois and interpret the results. How would you describe the shape of the distribution? What would you expect to happen to the distribution as \(n\) gets larger?
Solution to Question 5
# use code cell to answer questions above
Practice: Finding Formulas for \(L(\theta)\)
Question 6
A sample \((x_1, x_2, x_3, x_4) = (1,3,3,2)\) is randomly selected from \(X \sim \mbox{Binom}(3,p)\). Give a formula the likelihood function.
Solution to Question 6
Question 7
Give a formula the likelihood function given the sample \(x_1, x_2, x_3, \ldots, x_n\) is randomly selected from \(X \sim \mbox{Exp}(\lambda)\).
Solution to Question 7
Practice: Maximizing the Likelihood Function
Question 8
Using your answer from Question 6, find the MLE for \(p\) when \((x_1, x_2, x_3, x_4) = (1,3,3,2)\) is randomly selected from \(X \sim \mbox{Binom}(3,p)\).
Solution to Question 8
Steps for Finding MLE
Steps for finding MLE, \(\hat{\theta}_{\rm MLE}\):
- Find a formula the likelihood function.
\[L(\theta \mid x_1, x_2, \ldots , x_n) = f(x_1; \theta) f(x_2; \theta) \ldots f(x_n; \theta) = \prod_{i=1}^n f(x_i; \theta)\]
- Maximize the likelihood function.
- Take the derivative of \(L\) with respect to \(\theta\)
- Find critical points of \(L\) where \(\frac{dL}{d\theta}=0\) (or is undefined).
- Evaluate \(L\) at each critical point and identify the MLE.
- Check your work!
Plotting the Likelihood Function for Question 8
Running the code cell below will generate a plot of the likelihood function from Question 8. We should verify the maximum of the graph coincides with our answer to Question 8. There is nothing to edit in the code cell below.
p <- seq(0, 1, 0.01) # values of p on x-axis
like.binom <- 9 * p^9 * (1-p)^3 # values of L(p)
cv <- 9 * (0.75)^9 * (1-0.75)^3
plot(p, like.binom, # plot p and likelihood on x and y axes
type = "l", # connect plotted points with a curve
ylab = "L(p)", # y-axis label
xlab = "p", # x-axis label
main = "Plot of Likelihood Function") # main label
points(x = 0.75, y = cv, cex = 2, pch = 20, col = "tomato") # point at max
axis(1, at=c(0.75), label="theta = 0.75", col.axis = "tomato", pos=0.0015, cex = 1.5) # marking MLE estimate
abline(v = 0.75, col = "tomato", lwd = 2, lty = 2) # marking MLE estimate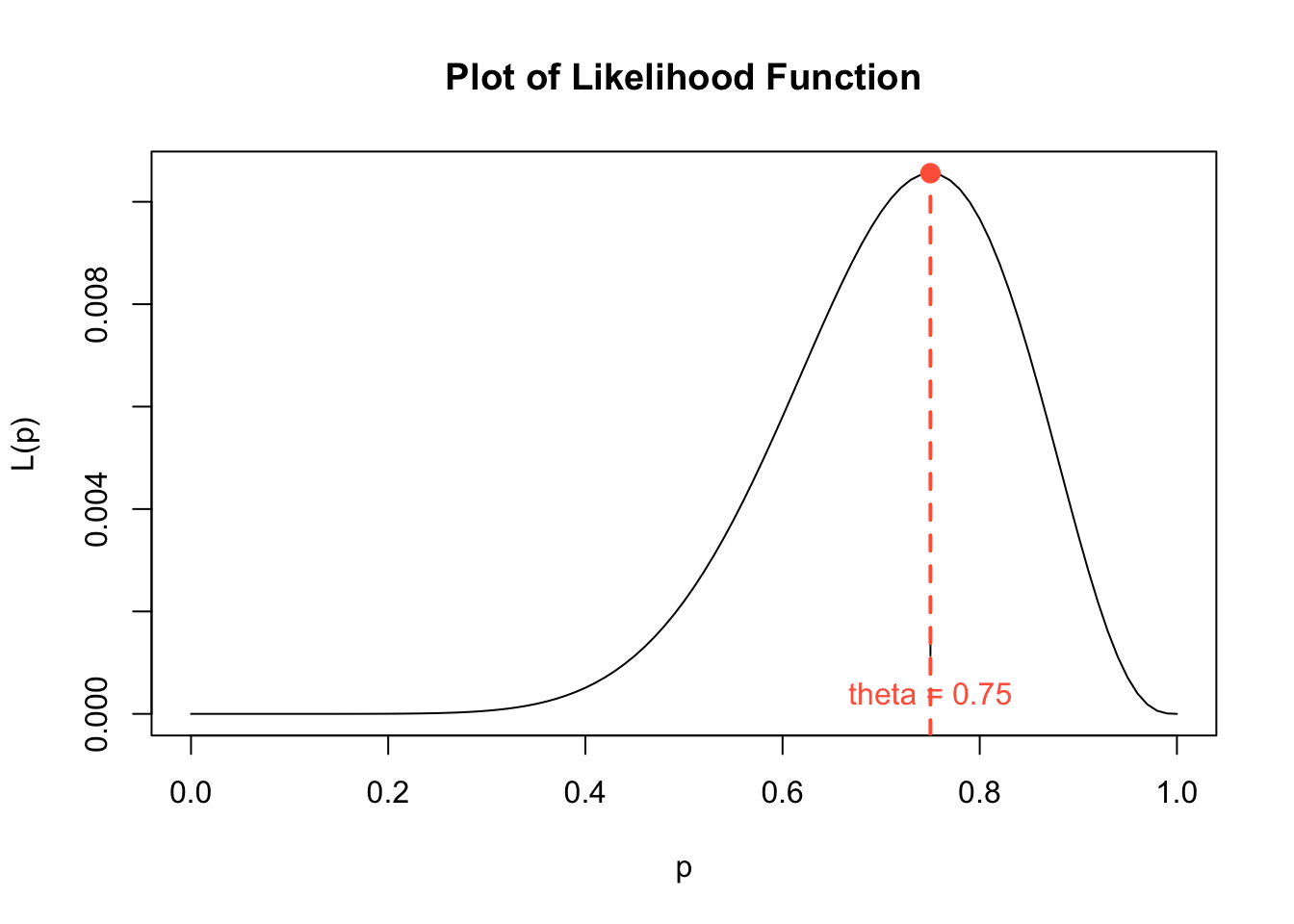
Question 9
Recall the sample from Question 6. Complete the code cell below to build a formula for the likelihood function and find the value of \(\hat{p}_{\rm{MLE}}\). Run the completed code cell to check your answer in Question 8.
Tip
- See earlier code for constructing the likelihood function and finding the maximum.
- When considering the interval option for
optimize(), keep in mind we are estimating the value of a proportion, \(p\).
Solution to Question 9
Replace each of the four ?? in the code cell below with appropriate code. Then run the completed code to compute the MLE estimate \(\hat{p}_{\rm{MLE}}\) for the sample x picked from \(X \sim \mbox{Binom}(3,p)\).
x <- c(1, 3, 3, 2) # given random sample
like.binom <- function(p){
pmf.binom <- ?? # replace ??
prod(??) # replace ??
}
optimize(??, ??, maximum = TRUE) # replace both ??Using the Log-Likelihood Function
Logarithmic functions such as \(y = \ln{x}\) are increasing functions. The larger the input \(x\), the larger the output \(y = \ln{x}\) becomes. Thus, the value of \(\theta\) that gives the maximum value of \(L(\theta)\) will also correspond to the value of \(\theta\) that gives the maximum value of the function \(y = \ln{(L(\theta))}\), and vice versa:
The value of \(\theta\) that maximizes functions \(y=\ln{(L(\theta}))\) is the value of \(\theta\) that maximizes \(L(\theta)\).
We call the the natural log of the likelihood function, \(\color{dodgerblue}{y=\ln{(L(\theta}))}\), the log-likelihood function.
Caution
In statistics, the term “log” usually means “natural log”. The notation \(\log{()}\) is often used to denote a natural log instead of using \(\ln{()}\). This can be confusing since you may have previously learned \(\log{()}\) implies “log base 10”. Similarly, in R:
- The function
log(x)is the natural log of x. - The function
log10(x)is the log base 10 of x.
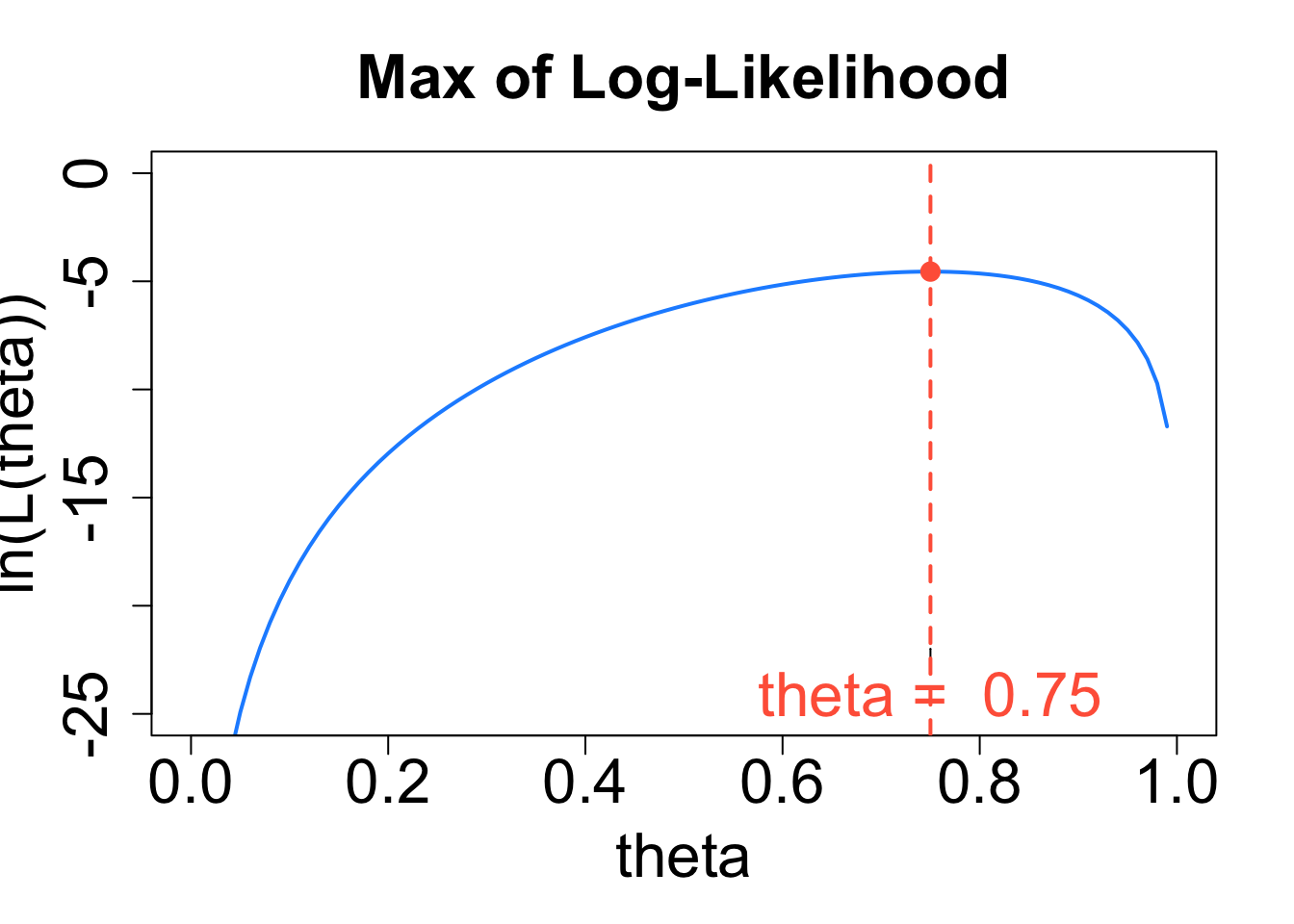
Why Maximize \(y=\ln{(L(\theta}))\) Instead of \(L(\theta)\)?
Consider the likelihood function from Question 7,
\[L({\color{tomato}\lambda}) = {\color{tomato}\lambda}^n e^{- {\color{tomato}\lambda} \sum_i x_i}.\] To find the critical values, we first need to find an expression for the derivative \(\frac{d L}{d \lambda}\).
- We need to apply the product rule.
- We need to apply the chain rule to compute the derivative of \(e^{- {\color{tomato}\lambda} \sum_i x_i}\).
- After finding an expression for the derivative, we would then need to solve a complicated equation.
- We can use key properties of the natural log to help make the differentiation easier!
Useful Properties of the Natural Log
The four properties of natural logs listed below will be helpful to recall when working with log-likelihood functions.
\(\ln{(A \cdot B)} = \ln{A} + \ln{B}\)
\(\ln{\left( \frac{A}{B} \right)} = \ln{A} - \ln{B}\)
\(\ln{(A^k)} = k \ln{A}\)
\(\ln{e^k} = k\)
Likelihood functions are by definition a product of functions and often involve \(e\). Taking the natural log of the likelihood function converts a product to a sum. It is much easier to take the derivative of sums than products!
Question 10
Give a simplified expression for the log-likelihood function corresponding to the likelihood function from the exponential distribution in Question 7,
\[L({\color{tomato}\lambda}) = {\color{tomato}\lambda}^n e^{- {\color{tomato}\lambda} \sum_i x_i}.\]
Solution to Question 10
Steps for Finding MLE Using a Log-Likelihood Function
Steps for finding MLE, \(\hat{\theta}_{\rm MLE}\), using a log-likelihood function:
- Find a formula the likelihood function.
\[L(\theta \mid x_1, x_2, \ldots , x_n) = f(x_1; \theta) f(x_2; \theta) \ldots f(x_n; \theta) = \prod_{i=1}^n f(x_i; \theta)\] 2. Apply the natural log to \(L(\theta)\) to derive the log-likelihood function \(y = \ln{(L(\theta))}\). Simplify using properties of the natural log before moving to the next step.
- Maximize the log-likelihood function.
- Take the derivative of \(y=\ln{(L(\theta))}\) with respect to \(\theta\)
- Find critical points of the log-likelihood function where \(\frac{dy}{d\theta}=0\) (or is undefined).
- Evaluate the log-likelihood function \(y=\ln{(L(\theta))}\) at each critical point and identify the MLE.
- Check your work!
Question 11
Find a general formula for the MLE of \(\lambda\) when \(x_1, x_2, x_3, \ldots, x_n\) comes from \(X \sim \mbox{Exp}(\lambda)\). Your answer will depend on the \(x_i\)’s.
Tip
- Maximize the log-likelihood function from Question 10.
- Be sure you simplify the log-likelihood before taking the derivative.
- Recall \(\lambda\) is the variable when differentiating, and treat each \(x_i\) as a constant.
Solution to Question 11
Analytic Results
In Question 11, we found a general formula for \(\hat{\lambda}_{\rm{MLE}}\), the MLE of exponential distributions in general. We cannot use R to numerically check our analytic results since our result is a formula that depends on the values of the \(x_i\)’s. We can test our formula on many different random samples and check to make sure our formula gives consistent answers with numeric solutions in R. Using calculus to derive the general formula for \(\hat{\lambda}_{\rm{MLE}}\) in Question 11 is incredibly convenient since now we have a “shortcut” formula that we can use for finding MLE estimates for any random sample from an exponential distributions.
Question 12
Find a general formula for the MLE of \(\lambda\) when \(x_1, x_2, x_3, \ldots, x_n\) comes from \(X \sim \mbox{Pois}(\lambda)\). Your answer will depend on the \(x_i\)’s.
Solution to Question 12
Question 13
Suppose a random variable with \(X_1=5\), \(X_2=9\), \(X_3=9\), and \(X_4=10\) is drawn from a distribution with pdf
\[f(x; \theta) = \frac{\theta}{2\sqrt{x}}e^{-\theta \sqrt{x}}, \quad \mbox{where x $>0$}.\]
Find an MLE for \(\theta\).
Solution to Question 13
Question 14
Consider the random sample of \(n=40\) values picked from a geometric distribution \(X \sim \mbox{Geom}(p)\) that are stored in the vector x.geom. Note the proportion true.p is unknown for now.
- Run the code cell below to generate a random value for
true.p(which is hidden) and createx.geomwhich is printed to the screen.
set.seed(117) # fixes randomization of true.p and x.geom
true.p <- sample(seq(0.1, 0.9, 0.1), size=1) # true.p hidden for now
x.geom <- rgeom(40, true.p) # generate a random sample n=40
x.geom [1] 8 0 5 2 1 1 4 2 12 3 0 1 7 2 0 0 3 14 2 3 1 0 2 5 2
[26] 6 4 3 2 1 2 5 0 3 1 4 0 1 0 0Question 14a
Based on the sample stored in x.geom in the previous code cell, find the MLE estimate for \(\hat{p}_{\rm{MLE}}\).
- Complete and run the partially completed R code cell below.
Solution to Question 14a
Replace each of the four ?? in the code cell below with appropriate code. Then run the completed code to compute the MLE estimate \(\hat{p}_{\rm{MLE}}\) for the sample (size \(n=40)\) x.geom randomly selected from \(X \sim \mbox{Geom}(p)\).
# be sure you first run code cell above to define x.geom
like.geom <- function(p){
pmf.geom <- ?? # replace ??
prod(??) # replace ??
}
optimize(??, ??, maximum = TRUE) # replace both ??Question 14b
Complete the partially completed code cell below to generate a plot of a distribution of MLE’s for \(\hat{p}_{\rm{MLE}}\) based on 10,000 randomly selected samples from \(X \sim \mbox{Geom}(p)\).
Solution to Question 14b
Replace each of the five ?? in the code cell below with appropriate code. Then run the completed code to create and plot a distribution of MLE’s for samples size \(n=40\) from \(X \sim \mbox{Geom}(p)\).
mle.geom <- numeric(10000)
for (i in 1:10000)
{
x.temp <- ?? # replace ??, pick random sample size n=40
geom.like <- function(p){
geom.pmf <- ?? # replace ??
prod(??) # replace ??
}
mle.geom[i] <- optimize(??, ??, maximum = TRUE)$maximum # replace both ??
}
hist(mle.geom,
breaks = 20,
xlab = "MLE",
main = "Dist. of MLE's")
abline(v = true.p, col = "dodgerblue", lwd = 2) # actual value of p
abline(v = mean(mle.geom), col = "tomato", lwd = 2) # expected value of MLEQuestion 14c
Based on the distribution of MLE’s in Question 14b, do you believe the estimator \(\hat{p}_{\rm{MLE}}\) is unbiased or biased? Explain why or why not.
Solution to Question 14c
Summary of Results from Common Distributions
So far we have observed:
Poisson distributions: \(X \sim \mbox{Pois}(\lambda)\) have \(\displaystyle \hat{\lambda}_{\rm MLE} = \bar{x}\)
Binomial distributions: \(X \sim \mbox{Binom}(n,p)\) have \(\displaystyle \hat{p}_{\rm MLE} = \hat{p}\).
Exponential distributions: \(X \sim \mbox{Exp}(\lambda)\) have \(\displaystyle \hat{\lambda}_{\rm MLE} = \frac{1}{\bar{x}}\).
Geometric distributions: \(X \sim \mbox{Geom}(p)\) have \(\displaystyle \hat{p}_{\rm MLE} = \frac{1}{\bar{x}}\).
For normal distributions \(X \sim N(\mu, \sigma)\), the maximum likelihood estimates of \(\mu\) and \(\theta\) are \[\hat{\mu}_{\rm{MLE}} = \frac{1}{n} \sum_{i=1}^n x_i = \bar{x} \quad \mbox{ and } \quad \hat{\sigma}_{\rm{MLE}} = \sqrt{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2}.\]
- See this post for a derivation of the MLE formulas for \(\hat{\mu}_{\rm{MLE}}\) and \(\hat{\sigma}_{\rm{MLE}}\).
- These materials from Penn State also explain how to derive the MLE formulas for \(\hat{\mu}_{\rm{MLE}}\) and \(\hat{\sigma}_{\rm{MLE}}\).
Recap of Maximum Likelihood Estimates
- MLE’s give reasonable estimates that make sense!
- MLE’s are often good estimators since they satisfy several nice properties
- Consistency: As we get more data (sample size goes to infinity), the estimator becomes more and more accurate and converges to the actual value of \(\theta\).
- Normality: As we get more data, the distribution of MLE’s converge to a normal distribution.
- Variability: They have the smallest possible variance for a consistent estimator.
- The downside is finding MLE’s are not always easy (or possible).

Statistical Methods: Exploring the Uncertain by Adam Spiegler is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.